
티스토리 뷰
멀티캠퍼스 AI과정/05 Machine Learning
Machine Learning 10 - Tensorflow 2.1, K-NN
jhk828 2020. 10. 13. 07:541. 지난주 금요일 colab mnist 코드 실행 결과
2. 어제 멀티노미얼 코드 수정 1012
3. 1013 코드도//
가상환경을 구축한다.
-
가상환경 새로 구축
(base) C:\WINDOWS\system32>conda create -n data_env_tensorflow2 python=3.7 openssl -
필요한 라이브러리 설치
(base) C:\WINDOWS\system32>conda activate data_env_tensorflow2(data_env_tensorflow2) C:\WINDOWS\system32>conda install nb_conda(data_env_tensorflow2) C:\WINDOWS\system32>conda install numy, pandas, matplotlib, seaborn, sklearn, tensorflow
Tensorflow 2.0 변경 사항들
- Eager Execution : TF를 실행하는 방법이 변경되었다.
- Keras가 유일한 상위 API로 등장하여 구현 방식이 변화하였다.
Keras의 장점 - Modularity
- Loss
- Activation function
- Optimer
- Layer
# 버전 확인
import tensorflow as tf
print(tf.__version__) # 2.1.0
import numpy as np
import tensorflow as tf
# 랜덤값을 하나 얻어온다.
# 1) Numpy
random1 = np.random.rand(2,2)
print(random1)
# [[0.6695528 0.1078963 ]
# [0.23725594 0.18586521]]
# 2) Tensorflow
random2 = tf.random.normal([1], dtype=tf.float32)
print(random2) # Tensor가 출력된다.
# tf.Tensor([-0.38180086], shape=(1,), dtype=float32)
# TF 1.x 버전에서는 Node가 가지는 값을 얻어오려면 ( Node를 실행시키려면) Sessiond이 있어야 했다.
# TF 2.x 버전에서는 session 없이 즉시 실행시킬 수 있다. -> Eager Execution
print(random2.numpy())
# [-0.38180086]
import tensorflow as tf
a = tf.constant(10, dtype=tf.float32)
b = tf.constant(20, dtype=tf.float32)
c = a + b
# numpy()라는 함수로 세션의 값을 얻는다.
print('c의 값은 : {}'.format(c.numpy())) # c의 값은 : 30.0
d = 30.0
# 1차원 scalar 값을 tensor로 변환한다.
tensor_d = tf.convert_to_tensor(d)
print((c + tensor_d).numpy()) # 60.0
import tensorflow as tf
W = tf.Variable(tf.random.normal([1]), name='weight')
# 기존에는 tf.Variable()을 이용해서 변수를 만들면 사용하기 전에 반드시 초기화를 진행해야 했다.
# sess.run(tf.global_variables_initializer())
# TF 2.0에서는 초기화를 하지 않아도 된다.
print(W.numpy())
# [0.21090215]# tensorflow graph에 입력을 주는 부분이 없어졌다.
# 기존에는 graph에게 데이터를 밀어넣기 위해 placeholder를 이용했다.
# 이를 Lazy exection이라 부른다.
# TF 2.0에는 Eager Execution에 의해서 더이상 placeholder를 사용하지 않는다.
#############################################################################
# tensorflow의 keras를 이용하여 Model 생성
import tensorflow as tf
# from tensorflow.keras.model import Sequential
# model = Sequential() # keras model 생성
model = tf.keras.models.Sequential() # 1. keras model 생성
# 2. model을 만들었으니 그 다음에는 layer 생성
model.add(tf.keras.layers.Flatten(input_shape=(2, ))) # layer를 추가
model.add(tf.keras.layers.Dense(3, activation='softmax')) # output이 3개
# 3. model compile 과정
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=1e-3),
metrics=['accuracy'])
def my_loss:
pass
# model 학습
model.fit(x_data_train,
t_data_train,
epochs=100,
batch_size=100,
validation_split=0.3)

|
 |
 |
 |
Tensorflow 2.0으로 Multiple Linear Regression 구현
- Classical Linear Regression Model
-
Simple Linear Regression (단순 선형 회귀) -> 독립변수 1개
- Multiple Linear Regression (다중 선형 회귀) -> 독립변수 2개 이상
-
- Ozone 예제
- 태양광, 온도, 바람 ->ozone 양 예측
- sklearn, tensorflow 2.1 구현
- 결측치 처리
- Deletion 결측치 처리
- Listwise : 결측치가 존재하는 행 자체를 삭제
- Pairwise : 결측치만 삭제 (x)
- Imputation (결측치 보강)
- 1) 평균화 기법 (평균, median, 최빈값(mode))
- 평균 : 전체 -> grouping 평균
- 2) 예측 기법
- 독립변수가 아닌 경우 (종속 변수인 경우) 평균화 기법보다 더 좋은 성능을 낸다.
- KNN, Decision Tre, Regression ..
- 여기서는 sklearn을 이용하여 KNN ozone량 예측
- 1) 평균화 기법 (평균, median, 최빈값(mode))
- Deletion 결측치 처리
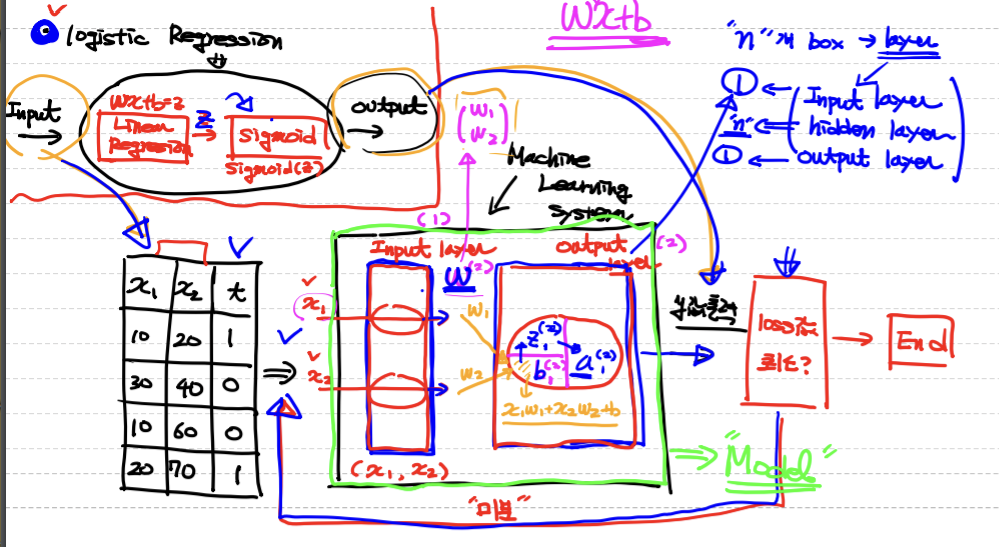
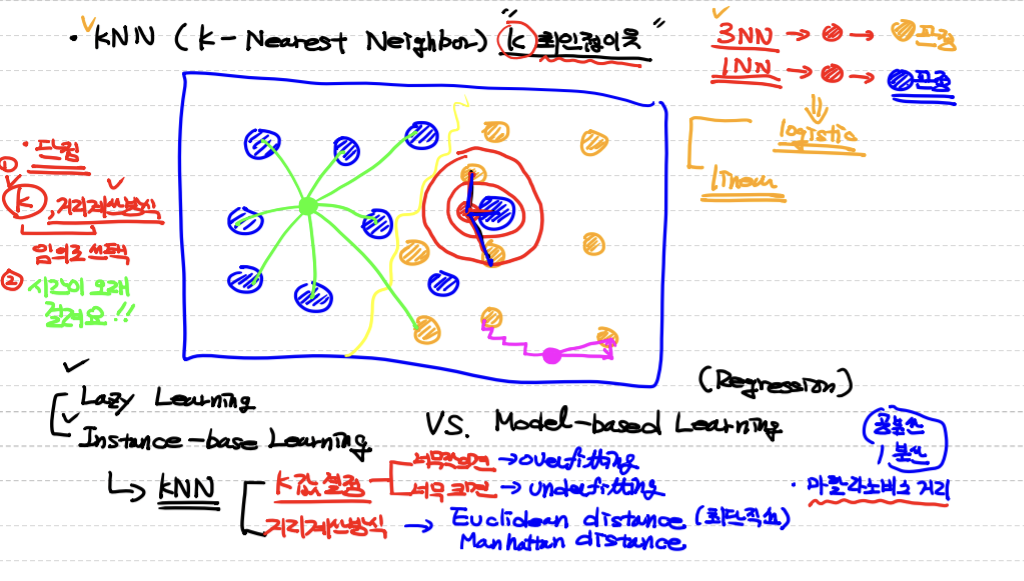
KNN (K-Nearest Neighbor)
# KNN 사용법 - sklearn
# BMI 예제를 학습한 후 정확도 측정
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
# Raw Data Loading
df = pd.read_csv('./data/bmi.csv', skiprows=3)
# data split
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(df[['height','weight']],
df['label'],
test_size=0.3,
random_state=0)
# Normalization
scaler = MinMaxScaler()
scaler.fit(x_data_train)
x_data_train_norm = scaler.transform(x_data_train)
x_data_test_norm = scaler.transform(x_data_test)
# Logistic Regression
model = LogisticRegression()
model.fit(x_data_train_norm, t_data_train)
print(model.score(x_data_test_norm, t_data_test)) # 0.9845
# KNN을 이용한 분류
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x_data_train_norm, t_data_train)
print(knn_model.score(x_data_test_norm, t_data_test)) # 0.998
'멀티캠퍼스 AI과정 > 05 Machine Learning' 카테고리의 다른 글
댓글