
티스토리 뷰
멀티캠퍼스 AI과정/06 Deep Learning
Deep Learning 09 - Transfer Learning (전이학습), Pretrained Network
jhk828 2020. 11. 5. 13:3420201104
Transfer Learning (전이학습)
학습 데이터가 부족한 분야의 모델 구축을 위해 데이터가 풍부한 분야에서 훈련된 모델을 재사용하는 머신러닝 학습 기법
- Pretrained Network
- Inception - Google
- ResNet - MS
- VGG - 연습
- CNN
- 기존 Network에서 Convolution Layer - 사용할 데이터 특성
- -> Feature Map 추출
- -> Classifier (분류기) (FC Layer)에 연결하여 학습
| Convolution Layer | FC Layer |
| 특성 추출 (Feature Extension) |
Classifier |
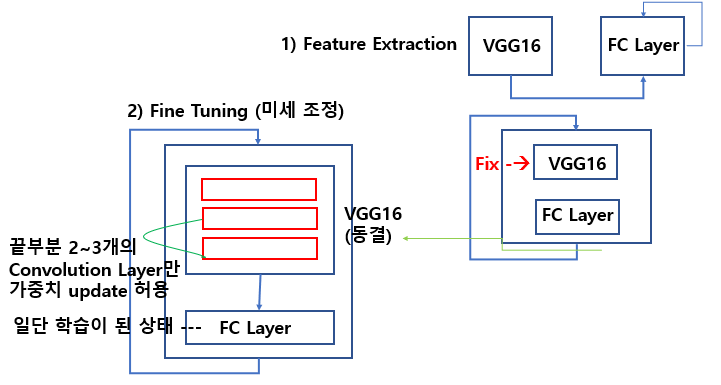
- 데이터 증식까지 포함한 model을 합쳐서 구현하고, Convolution Layer를 동결한다.
- 1) Feature (map) Extraction
- 기존 가중치는 그대로 나둔 뒤, 새로운 레이어를 추가해서 이를 학습하고 최종 결과를 내게끔 학습
- 2) Fine Tunung (미세 조정)
- 새로운 데이터로 다시한번 가중치를 세밀하게 조정하도록 학습. 기존 데이터는 기존대로 분류
- 1) Feature (map) Extraction
# 1104_cat_dog_transfer_learning_feature_extraction.ipynb
import tensorflow as tf
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# 특정 GPU에 1GB 메모리만 할당하도록 제한
try:
tf.config.experimental.set_visible_devices(gpus[1], 'GPU')
tf.config.experimental.set_virtual_device_configuration(
gpus[1],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)])
except RuntimeError as e:
# 프로그램 시작시에 가상 장치가 설정되어야만 합니다
print(e)
from tensorflow.keras.applications import VGG16
# VGG16은 Convolution Layer 16개, Fc Layer는 3개로 구성된 Network
base_model = VGG16(weights='imagenet',
include_top=False,
input_shape=(150,150,3))
base_model.summary()Output:
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
import os
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = './data/cat_dog_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1/255)
batch_size=20
def extract_feature(directory, sample_count):
features = np.zeros(shape=(sample_count,4,4,512))
labels = np.zeros(shape=(sample_count,))
generator = datagen.flow_from_directory(
directory,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
i = 0
for x_data_batch, t_data_batch in generator:
feature_batch = base_model.predict(x_data_batch)
features[i*batch_size:(i+1)*batch_size] = feature_batch
labels[i*batch_size:(i+1)*batch_size] = t_data_batch
i += 1
if i * batch_size >= sample_count:
break;
return features, labels
train_features, train_labels = extract_feature(train_dir,2000)
validation_features, validation_labels = extract_feature(validation_dir,1000)
test_features, test_labels = extract_feature(test_dir,1000)
Output:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
train_features = np.reshape(train_features, (2000,4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000,4 * 4 * 512))
test_features = np.reshape(test_features, (1000,4 * 4 * 512))
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import RMSprop
model = Sequential()
model.add(Dense(256,
activation='relu',
input_shape=(4 * 4 * 512,)))
model.add(Dropout(0.5))
model.add(Dense(1,
activation='sigmoid'))
model.compile(optimizer=RMSprop(learning_rate=2e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(train_features,
train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels)) Output:
## 생략
Epoch 27/30
100/100 [==============================] - 0s 5ms/step - loss: 0.1009 - accuracy: 0.9675 - val_loss: 0.2379 - val_accuracy: 0.9050
Epoch 28/30
100/100 [==============================] - 0s 5ms/step - loss: 0.0916 - accuracy: 0.9725 - val_loss: 0.2413 - val_accuracy: 0.9030
Epoch 29/30
100/100 [==============================] - 0s 5ms/step - loss: 0.0852 - accuracy: 0.9760 - val_loss: 0.2472 - val_accuracy: 0.9010
Epoch 30/30
100/100 [==============================] - 0s 5ms/step - loss: 0.0847 - accuracy: 0.9770 - val_loss: 0.2374 - val_accuracy: 0.9030
[ ]
1234567891011121314151617181920
%matplotlib inline
import matplotlib.pyplot as plt
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(train_acc, 'bo', color='r', label='training accuracy')
plt.plot(val_acc, 'b', color='b', label='validation accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
plt.plot(train_loss, 'bo', color='r', label='training loss')
plt.plot(val_loss, 'b', color='b', label='validation loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()밑에 생략
'멀티캠퍼스 AI과정 > 06 Deep Learning' 카테고리의 다른 글
| 윈도우 환경 mediapipe hand tracking (0) | 2020.11.25 |
|---|---|
| Deep Learning 08 - ImageDataGeneration / Image Augmentation (증식) / Transfer Learning (전이학습) (0) | 2020.11.05 |
| Deep Learning 07 - AWS에서 이미지 CNN 처리, cat/ dog 예제 2 (0) | 2020.11.02 |
| Deep Learning 07 - AWS에서 이미지 CNN 처리, cat dogs 예제 (0) | 2020.10.30 |
| Deep Learning 07 - AWS, CNN으로 MNIST 처리 (Tensorflow 2.x version) (0) | 2020.10.30 |
댓글